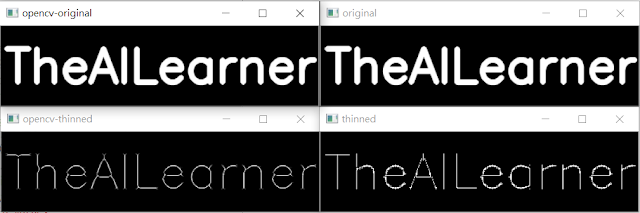
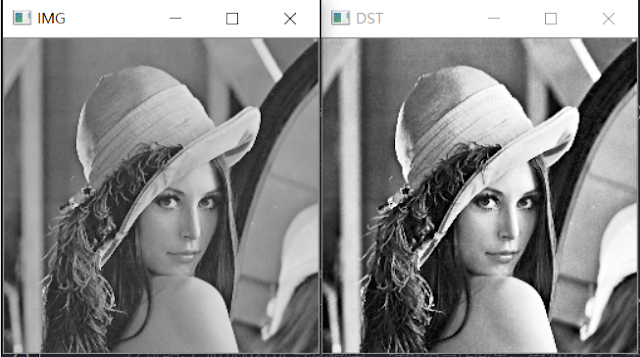
使用Python達成影像形態學處理(不使用Opencv函式庫)

1. 研究動機 在進入專題實驗室時,觀看 DeltaMOOCx 的線上課程,看到形態學的操作,覺得使用函式可以快速的達成功能,但是我不禁思考如果不使用函式,自己是否可以完成,本研究使用 opencv 的 cv2.getStructuringElement() 、 cv2.erode() 、 cv2.dilate() 、 cv2.morphologyEx() 函式當作對照組與不使用函式之結果進行比較。 2. 研究步驟 2.1 結構元素 (Structures Element) 結構元素為型態學的必備元素,結構元素的大小可以使用者自訂, opencv 函式中可以自訂為交叉 、 長方形 、 橢圓形 ,本研究對照組的 opencv 函式中使用的結構元素為 3x3 的交叉區塊,因此不使用 opencv 函式的實驗組的結構元素也為 3x3 的交叉區塊。 2.2 膨脹 (Dilation) 膨脹操作是將結構元素逐個像素的由上而下 、由左至右的掃描,假如結構元素的原點與被掃描圖像該點像素值相同,則將整個結構元素覆蓋至該圖像。 圖一 形態學膨脹操作 2.3 侵蝕 (Erosion) 侵蝕操作是將結構元素逐個像素的由上而下 、由左至右的掃描,假如整個結構元素與被掃描圖像像素值相同,則將結構元素的原點覆蓋至該圖像。 圖二 形態學侵蝕操作 2.4 斷開 (Open) 先侵蝕,接著再膨脹。 圖三 形態學斷開操作 2.5 閉合 (Close) 先膨脹,接著再侵蝕。 圖四 形態學閉合操作 3. 實驗結果 以下是實驗組與對照組的結果表格 : 4. 結論 經過了形態學的練習,不管事程式亦或是觀念都有一定的提升,我覺得可以把結構元素跟 圖像做捲積,再做加減運算,或許可以達成更快的速度。線上課程中,還有教到濾波,邊緣偵測等影像處理的方法,也是日後挑戰的題目。