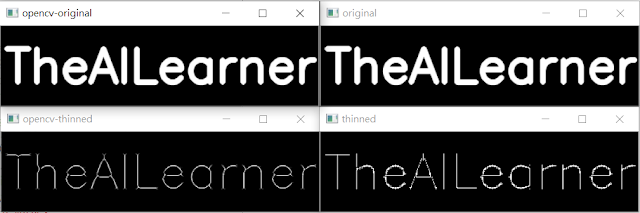
import numpy as np import cv2 img = np.zeros((100,400),dtype='uint8') font = cv2.FONT_HERSHEY_SIMPLEX cv2.putText(img,'TheAILearner',(5,70), font, 2,(255),5,cv2.LINE_AA) img1 = img.copy() x=img.shape[0] y=img.shape[1] thin = np.zeros(img.shape,dtype='uint8') def e(img2): b=np.uint8(np.zeros((x,y))) for i in range(1,x-1): for j in range(1,y-1): if (img2[i-1][j-1]==255 and img2[i-1][j+1]==255 and img2[i+1][j-1]==255 and img2[i+1][j+1]==255): b[i][j]=255#侵蝕 return b def o(img2): c=np.uint8(np.zeros((x,y))) for i in range(1,x-1): for j in range(1,y-1): if (img2[i-1][j-1]==255 and img2[i-1][j+1]==255 and img2[i+1][j-1]==255 and img2[i+1][j+1]==255): c[i][j]=255#侵蝕 d=c.copy() for i in range(1,x-1): for j in range(1,y-1): if (c[i][j]==255): d[i][j]=255 d[i-1][j-1]=255 d[i+1][j-1]=255